1.0 引言
本书旨在向你传授实用、高效(并尽可能优雅)的数值计算方法。我们始终假定你——读者——有特定的任务需要完成。我们的职责就是指导你如何着手进行这些任务。偶尔,我们可能会短暂地引导你走上一条特别优美的小径;但总体而言,我们会引领你沿着通往实用目标的主干道前行。
在本书中,你会看到我们毫不掩饰地发表评论,告诉你应该做什么、不应该做什么。这种规范性的语气源于我们有意识的决定,希望你不会觉得烦人。我们并不声称自己的建议是绝对正确的!相反,我们是在反对计算领域教科书中的一种倾向:罗列所有曾经发明过的方法,却从不对各种方法的相对优劣给出实用的判断。因此,只要可能,我们都会向你提供我们的实用判断。随着经验的积累,你会逐渐形成自己对我们建议可靠性的看法。请放心,我们的建议绝非完美无缺!
我们假定你能阅读 C++ 编写的计算机程序。“为什么选择 C++?”这个问题相当复杂。目前只需说明:我们希望选择一种在小规模上具有类 C 语法的语言(因为这对我们的读者群体来说最通用),同时具备丰富的面向对象编程功能(因为这是本第三版的重点),并且能高度向后兼容数值编程中一些虽旧但成熟可靠的技巧。这些要求几乎直接将我们引向了 C++,尽管 Java(以及密切相关的 C#)也曾是有力的竞争者。
坦率地说,我们必须指出,在《Numerical Repices》(Numerical Recipes)20 年的历史中,我们对科学计算编程语言未来发展的预测从未正确过,一次也没有!我们曾一度相信科学计算的未来潮流会是……Fortran……Pascal……C……Fortran 90(或 95 或 2000)……Mathematica……Matlab……C++ 或 Java……事实上,其中几种语言至今仍取得持续成功,并拥有大量用户(Pascal 除外!)。然而,目前没有任何一种语言在科学计算用户中占据多数,甚至未能获得显著的多数份额。
在本版中,我们不再试图预测编程语言的未来。相反,我们只是希望找到一种可行的方式来传达科学编程的思想。我们希望这些思想能够超越我们用来表达它们的语言——C++。
当我们在正文中包含程序时,它们看起来像这样:
void flmoon(const Int n, const Int nph, Int &jd, Doub &frac) {
const Doub RAD = 3.141592653589793238 / 180.0;
Int i;
Doub am, as, c, t, t2, xtra;
c = n + nph / 4.0;
t = c / 1236.85;
t2 = t * t;
as = 359.2242 + 29.105356 * c;
am = 306.0253 + 385.816918 * c + 0.010730 * t2;
jd = 2415020 + 28 * n + 7 * nph;
xtra = 0.75933 + 1.53058868 * c + ((1.178e-4) - (1.55e-7) * t) * t2;
if (nph == 0 || nph == 2)
xtra += (0.1734 - 3.93e-4 * t) * sin(RAD * as) - 0.4068 * sin(RAD * am);
else if (nph == 1 || nph == 3)
xtra += (0.1721 - 4.0e-4 * t) * sin(RAD * as) - 0.6280 * sin(RAD * am);
else
throw("nph is unknown in flmoon");
i = Int(xtra >= 0.0 ? floor(xtra) : ceil(xtra - 1.0));
jd += i;
frac = xtra - i;
}
我们的例程开头都有一段介绍性注释,概述其用途并解释调用方式。该例程用于计算月相。给定一个整数 n 和一个表示所需月相的代码 nph(nph = 0 表示新月,1 表示上弦月,2 表示满月,3 表示下弦月),该例程返回儒略日编号 jd 以及需加到该编号上的日的小数部分 frac,表示自 1900 年 1 月以来第 n 次该月相发生的时刻(假设使用格林尼治平太阳时)。
请注意我们处理所有错误和异常情况的约定:使用类似 throw("some error message"); 的语句。由于 C++ 没有为 char* 类型内置异常类,执行该语句会导致程序相当粗暴地中止。不过,我们将在 §1.5.1 中解释如何在不修改源代码的情况下获得更优雅的结果。
1.0.1 《Numerical Repices》不是什么
我们想利用本引言部分强调《Numerical Repices》不是什么:
-
《Numerical Repices》不是一本关于编程、最佳编程实践、C++ 或软件工程的教科书。我们并不反对良好的编程实践。只要有机会,我们会尽量传达良好的编程习惯——但这只是我们主要目的(即讲授实用数值方法的实际工作原理)的附带产物。一本优秀的编程(或软件工程)教科书所必需的风格统一性和功能服从标准化,在本书中并非我们的目标。本书每一节都聚焦于一种特定的计算方法。我们的目标是以尽可能清晰的方式解释和说明该方法。没有一种编程风格适用于所有方法,因此我们的风格会因章节而异。
-
《Numerical Repices》不是一个程序库。如果你是众多经常使用我们源代码的科学家和工程师之一,这可能会让你感到惊讶。我们的代码之所以不是一个程序库,是因为它要求用户投入比程序库应有的更高的智力投入。如果你没有阅读某个例程对应的章节,并逐行理解其工作原理,那么使用它将面临巨大风险!我们认为这是一个特性,而非缺陷,因为我们的首要目的是传授方法,而不是提供打包好的解决方案。本书不包含正式的练习题,部分原因在于我们认为每节的代码本身就是练习:如果你能理解代码的每一行,那么你很可能已经掌握了该节内容。
目前市面上有一些优秀的商业程序库 [1,2] 和集成数值计算环境 [3–5]。同样也有可比的免费资源,包括程序库 [6,7] 和集成环境 [8–10]。当你需要一个打包好的解决方案时,我们建议你使用这些资源之一。《Numerical Repices》是一本为厨师准备的食谱,而不是为食客提供的餐厅菜单。
1.0.2 常见问题解答
本节面向那些希望立即上手的读者。
- 如何在我的程序中使用 NR 例程?
最简单的方法是在你的程序顶部加入若干 #include 语句。始终以 nr3.h 开头,因为它定义了一些必要的工具类和函数(更多内容见 §1.4)。例如,下面的程序计算 1900 年 1 月之后前 20 次满月的儒略日编号的均值和方差。(这可真是一对有用的数据!)
#include "nr3.h"
#include "calendar.h"
#include "moment.h"
Int main(void) {
const Int NTOT = 20;
Int i, jd, nph = 2;
Doub frac, ave, vrnce;
VecDoub data(NTOT);
for (i = 0; i < NTOT; i++) {
flmoon(i, nph, jd, frac);
data[i] = jd;
}
avevar(data, ave, vrnce);
cout << "Average = " << setw(12) << ave;
cout << " Variance = " << setw(13) << vrnce << endl;
return 0;
}
请确保 NR 源代码文件位于编译器能够找到并 #include 的位置。编译并运行上述文件。(这部分操作我们无法告诉你怎么做。)输出结果应类似于:
Average = 2.41532e+06 Variance = 30480.7
- 那么,我究竟如何获得 NR 源代码的计算机文件呢?
你可以在网站 http://www.nr.com 购买代码订阅服务或一次性代码下载,也可以通过剑桥大学出版社发行的介质获取代码(例如通过 Amazon.com 或你喜爱的线上或实体书店)。代码附带个人单用户许可证(参见第 xix 页的“许可证与法律信息”)。本书(或其电子版)与代码许可证分开销售,是为了帮助降低各自的价格。此外,将产品分开也更能满足更多用户的需求:你的公司或教育机构可能已拥有站点许可证——请向他们咨询。
- 我如何知道需要
#include哪些文件?要理清所有例程之间的依赖关系实在太难了。
每个代码清单旁边的页边处都标注了其所在的源代码文件名。列出你所使用的源代码文件,然后访问 http://www.nr.com/dependencies,点击每个源代码文件的名称。这个交互式网页将返回一个满足所有依赖关系所需的 #include 文件列表,并按正确顺序排列。图 1.0.1 展示了这一过程的大致工作方式。
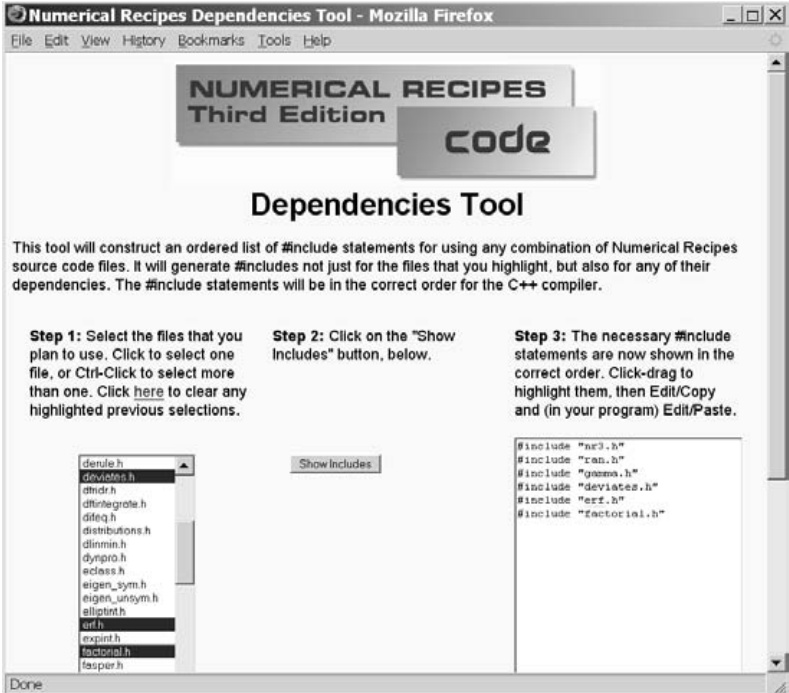
图 1.0.1. 位于 http://www.nr.com/dependencies 的交互式页面可为任意组合的 Numerical Recipes 例程解析依赖关系,并给出所需 #include 文件的有序列表。
- 这些 Doub、Int、VecDoub 等到底是什么?
我们总是使用自定义类型,而不是内置类型,以便在必要时可以重新定义它们。这些定义位于 nr3.h 中。通常,正如你所猜测的那样,Doub 表示 double,Int 表示 int,依此类推。我们的约定是所有自定义类型的名称都以大写字母开头。VecDoub 是一个向量类类型。有关我们类型的具体细节,请参见 §1.4。
- 什么是《Numerical Repices》网络笔记(Numerical Recipes Webnotes)?
《Numerical Repices》网络笔记是可通过网络访问的文档,其中包含一些代码实现清单或其他高度专业化的主题,这些内容未包含在纸质版书籍中。所有网络笔记的列表位于:
| 已测试的操作系统和编译器 | |
|---|---|
| 操作系统 | 编译器 |
| Microsoft Windows XP SP2 | Visual C++ 版本 14.00(Visual Studio 2005) |
| Microsoft Windows XP SP2 | Visual C++ 版本 13.10(Visual Studio 2003) |
| Microsoft Windows XP SP2 | Intel C++ 编译器 版本 9.1 |
| Novell SUSE Linux 10.1 | GNU GCC (g++) 版本 4.1.0 |
| Red Hat Enterprise Linux 4(64位) | GNU GCC (g++) 版本 3.4.6 和 版本 4.1.0 |
| Red Hat Linux 7.3 | Intel C++ 编译器 版本 9.1 |
| Apple Mac OS X 10.4(Tiger)Intel Core | GNU GCC (g++) 版本 4.0.1 |
http://www.nr.com/webnotes。通过将一些专业化的内容移至网络笔记中,我们能够控制纸质书的篇幅和价格。网络笔记会自动包含在电子版书籍中;请参见下一问题。
- 我属于“后纸质时代”的人。我希望在笔记本电脑上使用《Numerical Repices》。我在哪里可以获取完整、完全电子化的版本?
《Numerical Repices》提供按年订阅的完全电子版。你可以选择订阅电子版,代替或补充纸质版书籍。订阅内容可通过网络访问、下载和打印,并且与任何纸质版本不同,它始终包含最新的勘误内容。由于电子版不受纸质版页数限制,它将随着时间推移通过增加全新的章节而不断扩展,这些新章节仅以电子形式提供。我们认为,这代表了《Numerical Repices》乃至技术参考书籍未来的方向。我们预计会采用多种电子格式,并随着显示技术和版权管理技术的持续改进而不断更新:我们非常重视用户的便利性和可用性。更多信息请访问 http://www.nr.com/electronic。
- 《Numerical Repices》中有错误吗?
当然有!目前,大多数《Numerical Repices》代码已经过大量用户的长期使用,但新的错误肯定还会出现。请访问 http://www.nr.com 了解已知错误的信息,或报告你发现的新错误。
1.0.3 计算环境与程序验证
本书中的代码应当无需修改即可在任何符合 ANSI/ISO C++ 标准的编译器上运行,例如 Stroustrup 的著作 [11] 中所描述的标准。
作为大量硬件和软件配置的代表,我们已在上表所示的操作系统和编译器组合上测试了本书中的所有代码。
在验证代码时,我们直接从书籍手稿的机器可读形式中提取代码,因此我们测试的正是印刷的内容。(当然,这并不意味着代码完全没有错误!)
1.0.4 关于参考文献
在本书大多数章节的末尾,你会找到参考文献以及进一步阅读的建议。正文中的参考文献以方括号数字形式引用,例如 [12]。
我们并不声称本书在文献引用方面具有任何程度的完整性。对于那些已有大量二级文献(如教科书中的讨论、综述文章等)的主题,我们通常仅列出少数更有用的二级文献,尤其是那些对原始文献有良好引用的资料。当现有的二级文献不足时,我们会提供一些原始文献作为进一步阅读的起点,而非提供该领域的完整书目。
由于研究工作持续进展,我们对许多主题的参考文献不可避免地已经过时,或即将过时。我们尽量包含一些较老但适合进行“前向”网络搜索的参考文献:通过搜索引用了所列文献的更新论文,你应该能找到最新的研究成果。
网络参考文献和 URL 存在一个问题,因为我们无法保证当你查找时它们仍然存在。像“2007+”这样的日期表示“该链接在 2007 年时是有效的”。我们尽量提供足够完整的引用信息,即使文档已从所列位置移动,你也能通过网络搜索找到它。
参考文献的排列顺序不一定具有特殊意义。它是在“按引用顺序排列”和“按进一步阅读建议的大致优先级排列(最有用的排在前面)”之间的一种折中。
1.0.5 关于“高级主题”
以较小字号排版的内容(如此处所示)表示“高级主题”,这类内容要么超出了本章的主要论述范围,要么要求读者具备超出通常假设的数学背景,或者(少数情况下)包含更具推测性的讨论或未经充分测试的算法。如果你在首次阅读本书时跳过这些高级主题,不会遗漏任何重要内容。
以下是一个根据日历日期计算儒略日数(Julian Day Number)的函数。
calendar.h
在此例程中,julday 返回由月 mm、日 id 和年 iyyy(均为整型变量)指定的日历日期中午开始的儒略日数。正数年份表示公元(A.D.);负数年份表示公元前(B.C.)。请注意,公元前 1 年之后是公元 1 年。
const Int IGREG=15+31*(10+12*1582);
Int ja, jul, jy=iyyy, jm;
if (jy == 0) throw("julday: there is no year zero");
if (jy < 0) ++jy;
if (mm > 2) {
jm=mm+1;
} else {
--jy;
jm=mm+13;
}
jul = Int(floor(365.25*jy)+floor(30.6001*jm)+id+1720995);
if (id+31*(mm+12*iyyy) >= IGREG) {
ja=Int(0.01*jy);
jul += 2-ja+Int(0.25*ja);
}
return jul;
以下是其逆函数。
calendar.h
void caldat(const Int julian, Int &mm, Int &id, Int &iyyy) {
// 上述 julday 函数的逆函数。此处 julian 作为儒略日数输入,
// 例程输出 mm、id 和 iyyy,分别表示指定儒略日中午开始的月、日和年。
const Int IGREG=2299161;
Int ja,jalpha,jb,jc,jd,je;
if (julian >= IGREG) {
// 公历改革产生的修正:
jalpha=Int((Doub(julian-1867216)-0.25)/36524.25);
ja=julian+1+jalpha-Int(0.25*jalpha);
} else if (julian < 0) {
ja=julian+36525*(1-julian/36525);
} else {
ja=julian;
}
jb=ja+1524;
jc=Int(6680.0+(Doub(jb-2439870)-122.1)/365.25);
jd=Int(365*jc+(0.25*jc));
je=Int((jb-jd)/30.6001);
id=jb-jd-Int(30.6001*je);
mm=je-1;
if (mm > 12) mm -= 12;
iyyy=jc-4715;
if (mm > 2) --iyyy;
if (iyyy <= 0) --iyyy;
if (julian < 0) iyyy -= 100*(1-julian/36525);
}
作为练习,你可以尝试结合本节中的这些函数以及 §1.0 中的 f1moon 函数,搜索未来发生在星期五 13 号的满月。(答案,以 GMT-5 时区为准:2019 年 9 月 13 日和 2049 年 8 月 13 日。)有关适用于各种历史历法的更多历法算法,请参见 [13]。
参考文献
Visual Numerics, 2007+, IMSL Numerical Libraries, at http://www.vni.com.[1]
Numerical Algorithms Group, 2007+, NAG Numerical Library, at http://www.nag.co.uk.[2]
Wolfram Research, Inc., 2007+, Mathematica, at http://www.wolfram.com.[3]
The MathWorks, Inc., 2007+, MATLAB, at http://www.mathworks.com.[4]
Maplesoft, Inc., 2007+, Maple, at http://www.maplesoft.com.[5]
GNU Scientific Library, 2007+, at http://www.gnu.org/software/gsl.[6]
Netlib Repository, 2007+, at http://www.netlib.org.[7]
Scilab Scientific Software Package, 2007+, at http://www.scilab.org.[8]
GNU Octave, 2007+, at http://www.gnu.org/software/octave.[9]
R Software Environment for Statistical Computing and Graphics, 2007+, at http://www.r-project.org.[10]
Stroustrup, B. 1997, The C++ Programming Language, 3rd ed. (Reading, MA: Addison-Wesley).[11]
Meeus, J. 1982, Astronomical Formulae for Calculators, 2nd ed., revised and enlarged (Richmond, VA: Willmann-Bell).[12]
Hatcher, D.A. 1984, "Simple Formulae for Julian Day Numbers and Calendar Dates," Quarterly Journal of the Royal Astronomical Society, vol. 25, pp. 53–55; see also op. cit. 1985, vol. 26, pp. 151–155, and 1986, vol. 27, pp. 506–507.[13]
1.1 误差、精度与稳定性
计算机存储数字并非使用无限精度,而是采用某种近似表示,这种表示可以打包进固定数量的比特(二进制位)或字节(8 位一组)中。几乎所有计算机都允许程序员在多种不同的此类表示或数据类型之间进行选择。数据类型不仅可以在所用比特数(字长)上有所不同,更根本的区别在于所存储的数字是以定点(如 int)还是浮点(如 float 或 double)格式表示。
整数表示下的数字是精确的。整数表示下的算术运算也是精确的,前提是:(i) 结果未超出可表示的(通常为有符号)整数范围;(ii) 除法被解释为产生整数结果,舍弃任何余数。
1.1.1 浮点表示
在浮点表示中,一个数字在内部由一个符号位 (解释为正或负)、一个精确的整数指数 和一个精确表示的二进制尾数 组成。它们共同表示如下数值:
其中 是表示的基数(几乎总是 ), 是指数的偏置,对于任何给定的机器和表示,它是一个固定的整数常量。
| 值 | ||||
|---|---|---|---|---|
| float | 任意 | -- | 任意 | |
| 任意 | 非零 | |||
| 任意 | 非零 | NaN | ||
| double | 任意 | -- | 任意 | |
| 任意 | 非零 | |||
| 任意 | ||||
| 任意 | 非零 | NaN | ||
| *非规格化值 | ||||
原则上,多个浮点位模式可以表示同一个数字。例如,若 ,尾数的高位(高阶)零位可以左移(即乘以 2 的幂),同时将指数减去相应的补偿量。那些“尽可能左移”的位模式称为规格化(normalized)形式。
几乎所有现代处理器都采用相同的浮点数据表示,即 IEEE 754-1985 标准 [1] 中规定的表示。(关于非标准处理器的讨论,参见 §22.2。)对于 32 位 float 值,指数用 8 位表示(),尾数用 23 位;对于 64 位 double 值,指数用 11 位(),尾数用 52 位。对于大多数非零浮点值,尾数还使用了一个额外技巧:由于规格化尾数的最高位始终为 1,因此存储的尾数位被视为前面有一个值为 1 的“隐含”位。换句话说,尾数 的数值为 ,其中 (称为小数部分)由实际存储的位(23 或 52 位)组成。这一技巧略微提高了精度。
以下是 IEEE 754 标准中 double 值的一些表示示例:
你可以通过如下代码检查任意值的表示:
union Udoub {
double d;
unsigned char c[8];
};
void main() {
Udoub u;
u.d = 6.5;
for (int i=7;i>=0;i--) printf("%02x",u.c[i]);
printf("\n");
}
这是 C 语言,且为过时的风格,但可以运行。在包括 Intel Pentium 及其后续处理器在内的大多数处理器上,你会得到打印结果 401a000000000000,将其每个十六进制数字展开为四位二进制数后,即为公式 (1.1.2) 的最后一行。如果你得到的字节(两个十六进制数字为一组)顺序相反,则说明你的处理器是大端序(big-endian)而非小端序(little-endian):IEEE 754 标准并未规定(也不关心)浮点值中的字节存储顺序。
IEEE 754 标准还包括正负无穷大、正负零(计算上视为等价)以及 NaN(“非数字”)的表示。上页表格详细说明了这些表示方式。
如表所示,表示某些非规格化值的原因是为了使“下溢为零”的过程更加平滑。对于越来越小的数值序列,在越过最小可规格化值(其量级为 或 ;见表格)后,尾数的最高位开始右移。尽管你会逐渐损失精度,但直到再经过 23 或 52 位后,才会真正下溢为零。
当某个例程需要了解浮点表示的属性时,可以引用 C++ 标准库中的 numeric_limits 类。例如,numeric_limits<double>::min() 返回最小的规格化 double 值,通常为 。更多相关内容见 §22.2。
1.1.2 舍入误差
浮点表示下的数字之间的算术运算并非精确的,即使操作数恰好能被精确表示(即具有公式 1.1.1 形式的精确值)。例如,两个浮点数相加时,首先将较小(绝对值意义上)操作数的尾数右移(即除以 2),同时增加其指数,直到两个操作数的指数相同。在此过程中,较小操作数的低位(最低有效位)会因移位而丢失。如果两个操作数的量级相差过大,那么较小的操作数实际上会被替换为零,因为它被右移到了“ oblivion”(完全丢失)。
当加到浮点数 1.0 上时,能使结果不同于 1.0 的最小(绝对值意义上)浮点数称为机器精度 。IEEE 754 标准的 float 类型 约为 ,而 double 类型约为 。这些值可通过例如 numeric_limits<double>::epsilon() 获得。(关于机器特性的更详细讨论见 §22.2。)粗略地说,机器精度 是浮点数表示的相对精度,对应于尾数最低有效位变化 1 所引起的相对误差。几乎任何浮点数之间的算术运算都应被视为引入了至少 的额外相对误差。这种误差称为舍入误差。
必须理解的是, 并非机器上可表示的最小浮点数。后者取决于指数部分的位数,而 则取决于尾数部分的位数。
舍入误差会随着计算量的增加而累积。如果在计算某个值的过程中执行了 次此类算术运算,若舍入误差随机地上下波动,你可能会幸运地使总舍入误差达到 的量级。(平方根来源于随机游走。)然而,这一估计可能因以下两个原因而严重偏离实际:
(1) 通常情况下,你的计算规律或计算机的特性会导致舍入误差倾向于单向累积。此时总误差将达到 的量级。
(2) 某些特别不利的情况会极大地增加单次运算的舍入误差。通常,这类情况可归因于两个非常接近的数相减,导致结果中仅有(少数)低位有效位,即操作数不同的那些低位。你可能会认为这种“巧合”的相减不太可能发生,但事实并非总是如此。某些数学表达式会极大地增加此类情况发生的概率。例如,在求解二次方程的熟知公式中,
当 且 时,该加法运算变得敏感且容易产生舍入误差。(在 §5.6 中,我们将学习如何避免这一特定情况下的问题。)
1.1.3 截断误差
舍入误差是计算机硬件的特性。还存在另一种不同类型的误差,它是所用程序或算法本身的特性,与程序运行的硬件无关。许多数值算法通过计算“离散”的近似值来逼近所需的“连续”量。例如,数值积分通过在离散点集上计算函数值,而非在“所有”点上计算;又如,函数值可通过对其无穷级数的有限个首项求和来近似,而非求和全部无穷项。在这些情况下,存在一个可调参数(例如点数或项数),只有当该参数趋于无穷时,才能得到“真实”答案。任何实际计算都只能采用有限但足够大的参数值。
真实答案与实际计算所得答案之间的差异称为截断误差。即使在一台假想的“完美”计算机上(该计算机具有无限精度表示且无舍入误差),截断误差依然存在。通常而言,程序员对舍入误差无能为力,只能选择不会不必要地放大舍入误差的算法(参见下文关于“稳定性”的讨论)。而截断误差则完全在程序员的控制之下。事实上,说“巧妙地最小化截断误差几乎构成了数值分析领域的全部内容”也并不算过分夸张!
大多数情况下,截断误差与舍入误差之间并无强烈相互作用。可以设想,一次计算首先具有其在无限精度计算机上运行时的截断误差,再加上与所执行运算次数相关的舍入误差。
1.1.4 稳定性
有时,一个原本颇具吸引力的方法可能是不稳定的。这意味着,任何在计算早期阶段混入的舍入误差都会被逐级放大,直至淹没真实答案。一种不稳定的方法在假想的完美计算机上或许有用;但在现实世界中,我们必须要求算法是稳定的——或者,若算法不稳定,则必须极其谨慎地使用。
下面是一个简单(尽管略显人为)的不稳定算法示例:假设我们希望计算所谓“黄金比例”(Golden Mean)的所有整数次幂,该数定义为
可以验证(读者可轻松验证),幂次 满足一个简单的递推关系:
因此,已知前两个值 和 ,我们便可依次应用式 (1.1.5),每次仅需一次减法运算,而无需进行较慢的乘法运算(即每次乘以 )。
不幸的是,递推式 (1.1.5) 还有另一个解,即 。由于该递推关系是线性的,且这个不希望出现的解的绝对值大于 1,因此任何由舍入误差引入的微小该解成分都会呈指数增长。在典型的机器上,使用 32 位浮点数时,式 (1.1.5) 在 时便开始给出完全错误的结果,此时 已降至仅约 。因此,递推式 (1.1.5) 是不稳定的,不能用于上述目的。
在本书后续章节中,我们将以更复杂的形式多次遇到稳定性问题。
参考文献
IEEE, 1985, ANSI/IEEE Std 754–1985: IEEE Standard for Binary Floating-Point Numbers (New York: IEEE).[1]
Stoer, J., and Bulirsch, R. 2002, Introduction to Numerical Analysis, 3rd ed. (New York: Springer), Chapter 1.
Kahaner, D., Moler, C., and Nash, S. 1989, Numerical Methods and Software (Englewood Cliffs, NJ: Prentice-Hall), Chapter 2.
Johnson, L.W., and Riess, R.D. 1982, Numerical Analysis, 2nd ed. (Reading, MA: Addison-Wesley), §1.3.
Wilkinson, J.H. 1964, Rounding Errors in Algebraic Processes (Englewood Cliffs, NJ: Prentice-Hall).
1.2 C 语言家族语法
不仅 C++,还有 Java、C# 以及(在不同程度上)其他一些计算机语言,都与较早的 C 语言[1]共享大量小尺度语法。所谓小尺度,指的是内置类型上的运算、简单表达式、控制结构等。本节将回顾一些基础知识,给出一些良好编程的提示,并说明我们的一些约定和习惯。
1.2.1 运算符
第一条建议看似多余,却常常被忽视:你应该掌握所有 C 运算符及其优先级和结合性规则。你本人或许并不想将
写作 (对正整数 而言)的同义形式,但你绝对需要能够一眼看出
完全不是一回事!请每晚刷牙时都认真看看下一页的表格。偶尔为了清晰起见添加一些不必要的括号几乎算不上什么罪过,但习惯性地过度使用括号的代码却令人厌烦且难以阅读。
| C 和 C++ 中的运算符优先级与结合性规则 | |
| :: 作用域解析 | 从左到右 |
| () | 函数调用 |
| [ ] | 数组元素(下标) |
| . | 成员选择 |
| -> | 成员选择(通过指针) |
| ++ | 后置自增 |
| -- | 后置自减 |
| ! | 逻辑非 |
| ~ | 按位取反 |
| - | 一元负号 |
| ++ | 前置自增 |
| -- | 前置自减 |
| & | 取地址 |
| * | 取内容(解引用) |
| new | 创建 |
| delete | 销毁 |
| (type) | 类型转换 |
| sizeof | 字节大小 |
| * | 乘法 |
| / | 除法 |
| % | 取余 |
| + | 加法 |
| - | 减法 |
| << | 按位左移 |
| >> | 按位右移 |
| < | 算术小于 |
| > | 算术大于 |
| <= | 算术小于等于 |
| >= | 算术大于等于 |
| == | 算术等于 |
| != | 算术不等于 |
| & | 按位与 |
| ^ | 按位异或 |
| | | 按位或 |
| && | 逻辑与 |
| || | 逻辑或 |
| ? | 条件表达式 |
| = | 赋值运算符 |
| 还包括 +=, -=, *=, /=, %= | |
| <<=, >>=, &=, ^=, |= | |
| , | 顺序表达式 |
1.2.2 控制结构
这些对你来说应该都很熟悉。
循环。在 C 语言家族中,简单的循环通过 for 循环实现,例如:
for (j=2; j<=1000; j++) {
b[j] = a[j-1];
a[j-1] = j;
}
通常习惯将受控制结构影响的代码块缩进,而控制结构本身则不缩进。我们喜欢将起始的大括号 { 放在 for 语句的同一行,而不是下一行。这样可以节省一行空白,我们的出版商对此非常满意。
条件语句。条件语句(即 if 结构)在最一般的形式下如下所示:
if (...) {
...
}
else if (...) {
...
}
else {
...
}
然而,由于只有当代码块中包含多于一条语句时才需要使用大括号 {},因此 if 结构可以比上面所示的形式更简洁一些。但在编写嵌套的 if 子句时必须格外小心。例如,考虑以下代码:
if (b > 3)
if (a > 3) b += 1;
else b -= 1;
根据连续几行的缩进判断,这段代码的作者意图是:“如果 b 大于 3 且 a 大于 3,则 b 自增 1;如果 b 不大于 3,则 b 自减 1。” 然而,根据语言规则,实际含义却是:“如果 b 大于 3,则判断 a;如果 a 大于 3,则 b 自增 1;如果 a 小于或等于 3,则 b 自减 1。” 关键在于,else 子句总是与最近的未配对的 if 语句关联,无论你在代码中如何排版。这种语义上的混淆可以通过添加大括号来明确意图并改进程序。上述代码片段应写成:
if (b > 3) {
if (a > 3) b += 1;
}
else {
b -= 1;
}
while 循环。除了 for 循环外,还有 while 结构,例如:
while (n < 1000) {
n += 2;
j += 1;
}
控制条件(本例中为 n < 1000)在每次循环前都会被求值。如果条件不成立,则循环体内的语句不会被执行。特别地,如果在执行这段代码时 n 已经大于或等于 1000,那么循环体内的语句甚至一次都不会执行。
do-while 循环。与 while 循环相伴的是另一种控制结构,它在每次循环结束时测试控制条件:
do {
n += 2;
j += 1;
} while (n < 1000);
在这种情况下,循环体内的语句至少会执行一次,与 n 的初始值无关。
break 和 continue。当你有一个需要无限重复的循环,直到循环中间某处(可能在多个位置)测试的某个条件变为真时,你会使用 break 语句。此时你希望退出循环并继续执行后续代码。在 C 语言家族中,简单的 break 语句会终止最内层的 for、while、do 或 switch 结构的执行,并继续执行下一条顺序指令。典型用法可能是:
for (;;) {
...
if (...) break;
...
}
... // break 之后的下一条顺序指令
与 break 相伴的是 continue,它将程序控制转移到最内层包围的 for、while 或 do 语句体的末尾(即该语句体结束大括号的内部)。通常,这会导致执行与该循环体关联的下一次循环条件测试。
1.2.3 多“巧妙”才算太“巧妙”?
每个程序员偶尔都会忍不住写一两行代码,其精巧程度令人叹为观止,让所有阅读者都对其作者的智慧肃然起敬。但颇具讽刺意味的是,通常正是这位程序员自己,在日后试图理解自己的杰作时却一头雾水。例如,如果你想将值 循环置换为 ,你可能会一时得意地写下这样一行代码:
但你日后一定会后悔。更好的写法(而且很可能更快)是:
k = j + 1;
if (k == 3) k = 0;
另一方面,过于死板直白也可能是一种错误,或者至少不是最优的,比如:
switch (j) {
case 0: k = 1; break;
case 1: k = 2; break;
case 2: k = 0; break;
default: {
cerr << "unexpected value for j";
exit(1);
}
}
如果你是在一家拥有 名程序员的巨型公司工作,这(或类似风格)可能是公司规定的编码规范。但如果你是为自己做研究编程,或在一个小型协作团队中工作,这种风格很快会让你只见树木不见森林。你需要在晦涩的技巧和乏味的冗长之间找到适合自己的平衡点。一个好的原则是:你写的代码应该比你愿意阅读的代码稍微简单一点,但也仅此而已。
在“晦涩难懂”(坏)和“符合惯用法”(好)之间有一条微妙的界限。惯用法(idioms)是一些简短的表达式,它们要么足够常见,要么足够不言自明,因此可以自由使用。例如,通过以下方式测试整数 n 的奇偶性:
if (n & 1) ...
我们认为这远优于:
if (n % 2 == 1) ...
同样,我们喜欢通过如下方式将一个正整数翻倍:
n <<= 1;
或者通过如下方式构造一个包含 n 个比特位的掩码(mask):
(1 << n) - 1
等等。
有些惯用法即使不是那么显而易见,也值得考虑。S.E. Anderson [2] 收集了许多“位操作技巧”(bit-twiddling hacks),我们在此展示其中三个:
测试语句
if ((v & (v - 1)) == 0) {} // 是 2 的幂或零。
用于判断 v 是否为 2 的幂。如果你关心 v = 0 的情况,则必须写成:
if (v && ((v & (v - 1)) == 0)) {} // 是 2 的幂。
惯用法
for (c = 0; v; c++) v &= v - 1;
将正整数或无符号整数 v 中置位(=1)的比特位数量赋给 c(此过程会破坏 v 的值)。循环的迭代次数等于 v 中置位比特的数量。
惯用法
v--;
v |= v >> 1;
v |= v >> 2;
v |= v >> 4;
v |= v >> 8;
v |= v >> 16;
v++;
将一个正(或无符号)32 位整数 v 向上舍入到大于等于 v 的下一个 2 的幂。当我们使用这些位操作技巧时,会在代码中加入解释性注释。
1.2.4 工具宏或模板函数
文件 nr3.h 包含了以下函数的定义(以及其他内容):
MAX(a,b)
MIN(a,b)
SWAP(a,b)
SIGN(a,b)
除了最后一个,其余都很容易理解。SIGN(a,b) 返回一个数值,其绝对值与 a 相同,符号与 b 相同。这些函数均以模板内联函数的形式实现,因此可用于所有在语义上合理的参数类型。当然,也可以用宏来实现。
参考文献
Harbison, S.P., and Steele, G.L., Jr. 2002, C: A Reference Manual, 5th ed. (Englewood Cliffs, NJ: Prentice-Hall). [1]
Anderson, S.E. 2006, "Bit Twiddling Hacks," at http://graphics.stanford.edu/~seander/bithacks.html. [2]
1.3 对象、类与继承
对象(object)或类(class)(这两个术语可互换使用)是一种程序结构,它将若干变量、函数或两者组合在一起,使得其中所有变量和函数都能“看到”彼此并紧密交互,同时将大部分内部结构对其他程序结构和单元隐藏起来。对象使得面向对象编程(OOP)成为可能,而 OOP 已被公认为构建复杂软件几乎唯一成功的范式。OOP 的关键洞见在于:对象具有状态(state)和行为(behavior)。对象的状态由其成员变量中存储的值描述,而可能的行为则由成员函数决定。我们也会以其他方式使用对象。
围绕 OOP 的术语可能令人困惑。“对象”、“类”和“结构体”基本上指的是同一类事物。类中的成员函数通常被称为属于该类的“方法”(methods)。在 C++ 中,对象可通过关键字 class 或 struct 定义。然而,二者在隐藏对象内部细节的严格程度上有所不同。具体而言,
struct SomeName { ...
被定义为等同于
class SomeName {
public: ...
在本书中,我们始终使用 struct。这并非因为我们反对在面向对象编程(OOP)中使用 public 和 private 访问限定符,而是因为这种访问控制对于理解本书重点讨论的底层数值方法帮助甚微。事实上,访问限定符反而可能妨碍你的理解,因为
当你编写不同的测试用例并希望检查不同的内部变量(通常为 private)时,你将不得不频繁地在 private 和 public 之间来回移动这些成员。
由于我们的类是通过 struct 而非 class 声明的,因此使用“class”一词可能会引起混淆,我们将尽量避免使用它。因此,“object”实际上指的是 struct,而 struct 本质上就是一个类!
如果你是 OOP 的初学者,理解对象的定义与实例化之间的区别非常重要。你可以通过如下代码定义一个对象:
struct Twobar {
Doub a,b;
Twobar(const Doub aa, const Doub bb) : a(aa), b(bb) {}
Doub sum() {return a+b;}
Doub diff() {return a-b;}
};
这段代码并不会创建一个 Twobar 对象。它只是告诉编译器:当你在程序的后续部分要求创建该对象时(例如通过如下声明),应该如何创建:
Twobar mytwobar(3.,5.);
这会调用 Twobar 的构造函数,并创建(或实例化)一个 Twobar 的实例。在此例中,构造函数还将内部变量 a 和 b 分别设置为 3 和 5。你可以同时拥有任意多个互不干扰的实例:
Twobar anothertwobar(4.,6.);
Twobar athirdtwobar(7.,8.);
我们已经承诺过,本书并非面向对象编程或 C++ 语言的教材;因此我们在此不再深入。如果你需要更多相关内容,可参考优秀资料 [1-4]。
1.3.1 对象的简单用法
我们以各种方式使用对象,从简单到相当复杂,具体取决于所讨论的数值方法的需求。正如 §1.0 中提到的,这种不一致性意味着《Numerical Recipes》并不是一个程序库(或在 OOP 背景下的类库)的实用范例。这也意味着,在本书的某处,你很可能能找到数值计算中关于对象用法的各种可能示例!(我们希望你能将此视为优点。)
用于函数分组的对象。有时,一个对象仅仅用于将一组密切相关的函数组织在一起,这与使用命名空间(namespace)的方式相差不大。例如,第 6 章中 Erf 对象的简化形式如下:
struct Erf {
Doub erf(Doub x);
Doub erfc(Doub x);
Doub invert(Doub p);
Doub invertfc(Doub p);
Doub erfccheb(Doub z);
};
如 §6.2 中所述,前四个方法是供用户调用的,分别对应误差函数、互补误差函数及其两个对应的反函数。但这些方法共享部分代码,并且都使用了最后一个方法 erfccheb 中的公共代码,而用户通常会完全忽略该方法。因此,将整个集合组织为一个 Erf 对象是有意义的。这种做法唯一的缺点是,在使用(例如)erf 函数之前,你必须先实例化一个 Erf 对象:
在此处实例化对象实际上并不执行任何操作,因为 Erf 不包含任何变量(即没有存储状态)。它只是告诉编译器:你将使用哪个局部名称来引用其成员函数。(我们通常会将 Erf 的实例命名为 erf,但考虑到上面示例中 erf erf(3.) 可能会引起混淆,故未采用。)
用于标准化接口的对象。在 §6.14 中,我们将讨论若干有用的标准概率分布,例如正态分布、柯西分布、二项分布、泊松分布等。每种分布都有其独立的对象定义,例如:
struct Cauchydist {
Doub mu, sig;
Cauchydist(Doub mmu = 0., Doub ssig = 1.) : mu(mmu), sig(ssig) {}
Doub p(Doub x);
Doub cdf(Doub x);
Doub invcdf(Doub p);
};
其中,函数 p 返回概率密度,函数 cdf 返回累积分布函数(cdf),函数 invcdf 返回 cdf 的反函数。由于所有概率分布的接口保持一致,你只需修改程序中的一行代码,即可切换程序所使用的分布,例如从
Cauchydist mydist();
改为
Normaldist mydist();
此后所有对 mydist.p、mydist.cdf 等函数的引用都会自动随之改变。这几乎算不上真正的 OOP,但却非常方便。
用于返回多个值的对象。经常会出现这样的情况:一个函数计算出多个有用的量,但你并不知道用户在某次特定调用中究竟对哪一个或哪几个结果感兴趣。此时,一种便捷的对象用法是保存所有潜在有用的结果,然后让用户自行提取感兴趣的部分。例如,第 15 章中用于拟合直线 到数据点 和 的 Fitab 结构的简化版本如下:
struct Fitab {
Doub a, b;
Fitab(const VecDoub &xx, const VecDoub &yy);
};
(我们将在下文 §1.4 中讨论 VecDoub 及相关问题。)用户通过将数据点作为参数调用构造函数来计算拟合结果,
Fitab myfit(xx, yy);
那么两个“答案” 和 就分别可以通过 myfit.a 和 myfit.b 获得。我们将在本书中看到更多更复杂的例子。
为多次使用而保存内部状态的对象。这是经典的面向对象编程(OOP),名副其实。一个很好的例子是第 2 章中的 LUdcmp 对象,其(简化后的)形式如下:
struct LUdcmp {
Int n;
MatDoub lu;
LUdcmp(const MatDoub &a); // 构造函数。
void solve(const VecDoub &b, VecDoub &x);
void inverse(VecDoub &ainv);
Doub det();
};
该对象用于求解线性方程组和/或对矩阵求逆。使用时,你通过将你的矩阵 a 作为参数传入构造函数来创建一个实例。构造函数随后计算并存储你的矩阵的一个所谓的 分解(参见 §2.3)到内部矩阵 lu 中。通常你不会直接使用矩阵 lu(尽管如果你愿意也可以这么做)。相反,你现在可以使用以下方法:solve(),它对任意右端项 b 返回解向量 x;inverse(),它返回逆矩阵;以及 det(),它返回你的矩阵的行列式。
你可以按任意顺序调用 LUdcmp 的任意或全部方法;你很可能需要多次调用 solve,每次使用不同的右端项。如果你的问题中有多个矩阵,就为每个矩阵分别创建一个 LUdcmp 实例,例如:
LUdcmp alu(a), aalu(aa);
此后,alu.solve() 和 aalu.solve() 分别用于求解对应矩阵 a 和 aa 的线性方程组;alu.det() 和 aalu.det() 返回两个行列式;依此类推。
我们尚未穷尽对象的使用方式:接下来几节还会讨论更多用法。
1.3.2 作用域规则与对象销毁
最后一个例子 LUdcmp 引出了一个重要的问题:如何在程序中管理对象的时间和内存使用。
对于大型矩阵,LUdcmp 构造函数会执行大量计算。你可以通过在程序中合适的位置放置如下声明,明确指定该计算发生的位置:
LUdcmp alu(a);
面向对象语言(如 C++)与非面向对象语言(如 C)之间的一个重要区别在于:在后者中,声明只是对编译器的被动指令;而在前者中,声明是运行时可执行的语句。
对于大型矩阵,LUdcmp 构造函数还会占用大量内存来存储矩阵 lu。你该如何掌控这一点?也就是说,你如何表明该状态应保留足够长的时间,以供后续调用 alu.solve() 等方法使用,但又不应无限期保留?
答案在于 C++ 严格且可预测的作用域规则。你可以在任意位置通过写一个左花括号 “{” 来开启一个临时作用域,并通过匹配的右花括号 “}” 来结束该作用域。你可以按显而易见的方式嵌套作用域。任何在某个作用域内声明的对象,都会在该作用域结束时被销毁(其内存资源被释放)。例如:
MatDoub a(1000, 1000);
VecDoub b(1000), x(1000);
...
{
LUdcmp alu(a); // 创建对象 alu。
...
alu.solve(b, x); // 使用 alu。
...
} // 结束临时作用域。alu 中的资源被释放。
...
Doub d = alu.det(); // 错误!alu 已超出作用域。
此例假设你之后还会用到矩阵 a。否则,a 的声明本身也应放在临时作用域内。
请注意,所有由花括号界定的程序块都是作用域单元。这包括函数定义的主块,以及控制结构相关的块。例如,在如下代码中:
for (;;) {
...
LUdcmp alu(a);
...
}
每次迭代都会创建一个新的 alu 实例,并在该次迭代结束时销毁它。这有时可能是你期望的行为(例如,若矩阵 a 在每次迭代中都会变化);但你应小心避免无意中发生这种情况。
1.3.3 函数与函数对象(Functors)
本书中的许多例程以函数作为输入。例如,第 4 章中的数值积分(quadrature)例程以待积分的函数 作为输入。对于像 这样的简单情况,你可以简单地将该函数编码为:
Doub f(const Doub x) {
return x * x;
}
并将 f 作为参数传递给例程。然而,通常使用一个更通用的对象来向例程传递函数会更有用。例如, 可能依赖于其他变量或参数,这些参数需要从调用程序中传递进来;或者 的计算可能涉及程序其他部分的子计算或其他信息。在非面向对象编程中,这种通信通常通过全局变量实现,即信息“越过”接收函数参数 f 的例程直接传递。
C++ 提供了一种更好、更优雅的解决方案:函数对象(function objects)或 仿函数(functors)。仿函数就是一个重载了 operator() 的对象,使其能像函数一样返回函数值。(此处“functor”一词的用法与它在纯数学中的不同含义无关。)对于 的情况,现在可以编码为:
struct Square {
Doub operator()(const Doub x) {
return x * x;
}
};
要在数值积分或其他例程中使用它,你声明一个 Square 的实例:
Square g;
并将 g 传递给例程。在数值积分例程内部,调用 g(x) 会以常规方式返回函数值。
在上述例子中,使用仿函数而非普通函数并无优势。但假设你的问题中包含参数,例如 ,其中 和 需要从程序的其他地方传入。你可以通过构造函数设置这些参数:
```cpp
struct Contimespow {
Doub c, p;
Contimespow(const Doub cc, const Doub pp) : c(cc), p(pp) {}
Doub operator()(const Doub x) {
return c * pow(x, p);
}
};
在调用程序中,你可以通过如下方式声明 Contimespow 的一个实例:
Contimespow h(4., 0.5); // 将 c 和 p 传递给函子。
随后将 h 传递给相关例程。显然,你可以让函子变得更加复杂。例如,它可以包含其他辅助函数,以帮助计算函数值。
那么,我们是否应该将所有例程都实现为仅接受函子而不接受普通函数呢?幸运的是,我们不必做出这种抉择。我们可以编写例程,使其既能接受函数,也能接受函子。一个仅接受函数、并在区间 $a$ 到 $b$ 上进行积分的例程可能声明如下:
Doub someQuadrature(Doub func(const Doub), const Doub a, const Doub b);
为了使其能够同时接受函数或函子,我们将其改为模板函数:
template <class T>
Doub someQuadrature(T &func, const Doub a, const Doub b);
现在,编译器会自动判断你调用 someQuadrature 时传入的是函数还是函子,并生成相应的代码。如果你在程序的一个地方用函数调用该例程,而在另一个地方用函子调用,编译器也能正确处理。
本书将在许多需要函数参数的地方利用这一能力来传递函子。这极大地提高了灵活性和易用性。
按照惯例,当我们写 Ftor 时,指的是像上面的 Square 或 Contimespow 这样的函子;当我们写 fbare 时,指的是像上面 f 那样的“裸”函数;而当我们写 ftor(全小写)时,指的是函子的一个实例化对象,即类似如下声明:
Ftor ftor(...);
请将省略号替换为你自己的参数(如果有的话)。
当然,你为函子及其实例所取的名字会有所不同。当向一个模板化对象传递函数(该对象被设计为可接受函数或函子)时,语法会稍微复杂一些。例如,若该对象定义如下:
template <class T>
struct SomeStruct {
SomeStruct(T &func, ...); // 构造函数
...
};
那么,使用函子实例化它的方式如下:
Ftor ftor;
SomeStruct<Ftor> s(ftor, ...);
而使用函数实例化的方式则如下:
SomeStruct<Doub (const Doub)> s(fbare, ...);
在此例中,fbare 接受一个 const Doub 类型的参数并返回一个 Doub。当然,你必须根据你的具体情况使用相应的参数和返回类型。
1.3.4 继承
对象可以定义为从其他已定义的对象派生而来。在这种继承关系中,“父”类称为基类(base class),而“子”类称为派生类(derived class)。派生类拥有其基类的所有方法和存储状态,并可额外添加新的方法和状态。
“Is-a”关系。继承最直接的用途是描述所谓的“is-a”关系。面向对象编程(OOP)教材中充满了这样的例子:基类是 ZooAnimal,派生类是 Lion。换句话说,Lion “is-a” ZooAnimal。基类包含所有 ZooAnimal 共有的方法,例如 eat() 和 sleep(),而派生类则在基类基础上扩展了 Lion 特有的方法,例如 roar() 和 eat游客()。
在本书中,我们使用“is-a”继承的频率比你预期的要少。除了某些高度模式化的情形(例如优化的矩阵类:“三角矩阵 is-a 矩阵”),我们发现科学计算任务的多样性并不适合严格的“is-a”层次结构。当然也有例外。例如,在第7章中,我们定义了一个 Ran 对象,它提供了返回各种类型(如 Int 或 Doub)均匀随机数的方法。在该章后面,我们又定义了用于返回其他类型随机数(例如正态分布或二项分布)的对象。这些对象被定义为 Ran 的派生类,例如:
struct Binomialdev : Ran {
...
};
这样它们就可以复用 Ran 中已有的机制。这是一种真正的“is-a”关系,因为“二项分布随机数 is-a 随机数”。
另一个例子出现在第13章,其中 Daub4、Daub4i 和 Daubs 等对象均派生自 Wavelet 基类。这里的 Wavelet 是一个抽象基类(Abstract Base Class, ABC)[1,4],其自身不包含具体实现,而仅规定了所有 Wavelet 必须实现的方法接口。尽管如此,这种关系仍然是“is-a”关系:“Daub4 is-a Wavelet”。
“先决条件”关系。我们经常使用继承来将一组所需的方法作为先决条件传递给某个对象,并非出于任何教条式的原因,而仅仅是因为这样做很方便。当多个对象需要同一组先决条件时,这种做法尤其常见。在这种继承用法中,基类本身并不具备特定的“ZooAnimal”统一性;它可能只是一个杂项集合(grab-bag)。基类与派生类之间并不存在逻辑上的“is-a”关系。
第10章中的一个例子是 Bracketmethod,它作为多个最小化例程的基类,但其作用仅仅是提供一种用于初始括号化(bracketing)极小值的通用方法。在第7章中,Hastable 对象为其派生类 Hash 和 Mhash 提供了先决条件方法,但我们无法以任何有意义的方式说“Mhash 是一个 Hastable”。第6章中甚至有一个更极端的例子:基类 Gauleg18 除了向派生类 Beta 和 Gamma 提供高斯-勒让德积分所需的一组常量外,别无其他功能,而这两个派生类都需要这些常量。类似地,在第17章中,为了避免算法代码过于杂乱,基类向例程 StepperDopr853 和 StepperRoss 提供了冗长的常量列表。
部分抽象。继承也可以用于更复杂或特定场景的方式。例如,考虑第4章,其中像 Trapzd 和 Midpnt 这样的基本数值积分规则被用作构建更复杂积分算法的积木。这些简单规则共有的关键特性是:它们都提供了一种机制,通过向现有积分近似值中添加更多点,从而得到“下一阶段”的细化结果。这提示我们可以从一个名为 Quadrature 的抽象基类派生这些对象,该基类规定所有派生类必须拥有一个 next() 方法。这并不是对通用“is-a”接口的完整规范;它仅抽象出了一个被证明有用的功能。
例如,在§4.6中,Stiel 对象在不同情况下会调用两个不同的积分对象 Trapzd 和 D$E$rule。这两个对象不可互换:它们的构造函数参数不同,也无法轻易地都变成“ZooAnimal”(打个比方)。Stiel 当然了解它们之间的差异。然而,Stiel 的一个方法 quad() 并不需要(也不应该)了解这些差异。它只使用 next() 方法,而该方法在 Trapzd 和 D$E$rule 中均存在,但定义不同。
尽管处理此类情况有多种方式,但一旦 Trapzd 和 DErule 被赋予一个仅包含 next 虚接口的公共抽象基类 Quadrature,问题就变得简单了。在这种情况下,就 Stiel 的实现而言,基类只是一个次要的设计特性,几乎是一种事后补充,而非自顶向下设计的顶点。只要使用方式清晰明确,这种做法并无不妥。
第17章讨论常微分方程,其中包含一些更复杂的例子,结合了继承与模板。我们将在该章进一步讨论。
参考文献
Stroustrup, B. 1997, The C++ Programming Language, 3rd ed. (Reading, MA: Addison-Wesley).[1]
Lippman, S.B., Lajoie, J., and Moo, B.E. 2005, C++ Primer, 4th ed. (Boston: Addison-Wesley).[2]
Keogh, J., and Giannini, M. 2004, OOP Demystified (Emeryville, CA: McGraw-Hill/Osborne).[3]
Cline, M., Lomow, G., and Girou, M. 1999, C++ FAQs, 2nd ed. (Boston: Addison-Wesley).[4]
1.4 向量与矩阵对象
C++ 标准库 [1] 包含了一个相当不错的 vector<> 模板类。对其唯一的批评可能是:它功能过于丰富,以至于某些编译器厂商忽略了对其最基本操作(例如通过下标返回元素)进行极致的性能优化。这种性能在科学计算应用中极为重要;C++ 编译器偶尔缺乏这种优化,是许多科学家(在我们撰写本文时)仍使用 C 甚至 Fortran 编程的主要原因之一!
C++ 标准库中还包含 valarray<> 类。该类最初被设计为一种针对数值计算优化的类,具备一些与矩阵和多维数组相关的特性。然而,正如一位参与者所述:
valarray 类的设计并不完善。事实上,没有人尝试验证最终规范是否有效。之所以出现这种情况,是因为没有人对这些类“负责”。将 valarray 引入 C++ 标准库的人早在标准完成之前很久就离开了委员会。[1]
这段历史的结果是:C++ 目前至少拥有一个良好(但并非始终可靠优化)的向量类,却完全没有可靠的矩阵或多维数组类。该怎么办?我们将采用一种强调灵活性的策略,并仅假设向量和矩阵具备一组最小的属性。随后,我们将提供自己基础的向量和矩阵类。对于大多数编译器而言,这些类至少与 vector<> 以及其他常用向量和矩阵类一样高效。但如果你发现它们不够高效,也可以轻松切换到其他类,我们将在下文说明如何操作。
1.4.1 类型定义(Typedefs)
灵活性通过多层 typedef 类型间接实现,这些间接在编译时解析,因此不会带来运行时性能损失。第一层类型间接不仅适用于向量和矩阵,也适用于几乎所有变量:我们使用用户自定义类型名,而非 C++ 基本类型。这些定义位于 nr3.h 中。如果你遇到具有特殊内置类型的编译器,这些定义就是进行必要修改的“钩子”。完整的定义列表如下:
| NR 类型 | 通常定义 | 用途 |
|---|---|---|
| Char | char | 8 位有符号整数 |
| Uchar | unsigned char | 8 位无符号整数 |
| Int | int | 32 位有符号整数 |
| Uint | unsigned int | 32 位无符号整数 |
| Llong | long long int | 64 位有符号整数 |
| Ullong | unsigned long long int | 64 位无符号整数 |
| Doub | double | 64 位浮点数 |
| Ldoub | long double | [保留供将来使用] |
| Complex | complex | 2×64 位浮点复数 |
| Bool | bool | true 或 false |
当你需要修改 nr3.h 中的 typedef 时,例如你的编译器的 int 不是 32 位,或者不识别 long long int 类型,就可能需要调整这些定义。
你可能还需要替换为厂商特定的类型,例如 Microsoft 的 _int32 和 _int64。
第二层类型间接再次回到向量和矩阵的讨论。《数值 Recipes》源代码中出现的向量和矩阵类型如下。向量类型包括:VecInt、VecLint、VecChar、VecUchar、VecCharp、VecLlong、VecUllong、VecDoub、VecDoubp、VecComplex 和 VecBool。矩阵类型包括:MatInt、MatLint、MatChar、MatUchar、MatLlong、MatLlong、MatDoub、MatComplex 和 MatBool。从语义上讲,这些类型都应理解为元素类型对应上述用户自定义类型的向量和矩阵。以“p”结尾的类型表示其元素是指针,例如 VecCharp 是一个 char 指针(即 char*)的向量。如果你疑惑为何上述列表并非组合完备,那是因为本书并未使用 Vec、Mat、基本类型和指针的所有可能组合。你可以根据需要自行添加更多类似类型。
等等,还有更多!对于上述每种向量和矩阵类型,我们还定义了同名但带有后缀 __I、__O 和 __IO 的类型,例如 VecDoub_IO。我们在函数定义中使用这些带后缀的类型来指定参数类型。其含义分别是:参数为“输入”、“输出”或“输入输出”*。_I 类型会自动定义为 const。我们将在 §1.5.2 中进一步讨论此问题,主题为“const 正确性”。
你可能会觉得,既然少量模板类型就足以满足需求,我们却定义如此冗长的类型列表显得有些任性。但这样做的理由正是灵活性:你可以根据对程序效率、本地编码规范、const 正确性或其他需求的考虑,单独重新定义其中任意一种类型。事实上,在 nr3.h 中,所有这些类型都是通过如下方式 typedef 到一个向量类和一个矩阵类的:
typedef NRvector<Int> VecInt, VecInt_O, VecInt_IO;
typedef const NRvector<Int> VecInt_I;
...
typedef NRvector<Doub> VecDoub, VecDoub_O, VecDoub_IO;
typedef const NRvector<Doub> VecDoub_I;
...
typedef NRmatrix<Int> MatInt, MatInt_O, MatInt_IO;
typedef const NRmatrix<Int> MatInt_I;
...
typedef NRmatrix<Doub> MatDoub, MatDoub_O, MatDoub_IO;
typedef const NRmatrix<Doub> MatDoub_I;
...
因此(再次强调灵活性),你可以修改某个特定类型(如 VecDoub)的定义,也可以通过修改 NRvector<> 的定义来改变所有向量的实现。或者,你也可以直接保留我们在 nr3.h 中的定义。在 99.9% 的应用场景中,这应该都能很好地工作。
1.4.2 向量与矩阵类所需的方法
向量和矩阵类的关键之处不在于它们被 typedef 成什么名称,而在于它们被假定具备哪些方法(这些方法在 NRvector 和 NRmatrix 模板类中均已提供)。对于向量,所假定的方法是 C++ 标准库 vector<> 类方法的一个子集。如果 v 是类型为 NRvector<T> 的向量,则我们假定其具备以下方法:
- 构造函数,创建长度为零的向量。
- 构造函数,创建长度为
n的向量。 - 构造函数,将所有元素初始化为值
a。 - 构造函数,使用 C 风格数组
a[0],a[1], ... 中的值初始化元素。 - 拷贝构造函数。
- 返回
v中元素的数量。 - 将
v重设为大小newn。我们不假定原有内容会被保留。 - 将
v重设为大小newn,并将所有元素设为值a。 - 通过下标访问
v的元素,既可作为左值也可作为右值。 - 赋值运算符。如有必要会调整
v的大小,并使其成为向量rhs的副本。 - 使
T在外部可用(在模板函数或类中很有用)。
正如我们稍后将更详细讨论的那样,只要某个向量类提供了上述基本功能,你就可以在 Numerical Recipes 中使用任何你喜欢的向量类。例如,一种简单粗暴的方法是使用 C++ 标准库的 vector 类代替 NRvector,只需使用预处理器指令:
#define NRvector vector
(事实上,在文件 nr3.h 中有一个编译器开关 _USESTDVECTOR_,可以实现这一功能。)
矩阵类的方法与向量类非常类似。如果 vv 是一个类型为 NRmatrix<T> 的矩阵,我们假定它具有以下方法:
- 构造函数,创建零长度向量。
- 构造函数,创建 n × m 矩阵。
- 构造函数,将所有元素初始化为值
a。 - 构造函数,按行使用 C 风格数组中的值初始化元素。
- 拷贝构造函数。
- 返回行数
n。 - 返回列数
m。 - 将
vv重设为newn × newm。我们不假设内容会被保留。 - 将
vw重设为newn × newm,并将所有元素设为值a。 - 返回指向第
i行第一个元素的指针(通常不单独使用)。 - 通过下标访问
vw的元素,既可作为左值也可作为右值。 - 赋值运算符。如有必要,调整
vw的大小,并使其成为矩阵rhs的副本。 - 使类型
T对外部可见。
更精确的规范请参见 §1.4.3。
我们对向量和矩阵类还有一个额外的假设,即对象的所有元素都以连续顺序存储。对于向量,这意味着其元素可以通过相对于第一个元素的指针算术进行寻址。例如,如果我们有:
VecDoub a(100);
Doub *b = &a[0];
那么 a[i] 和 b[i] 引用的是同一个元素,无论是作为左值还是右值。这种能力有时对内层循环的效率至关重要,同时也便于与只能处理 Doub* 数组而不能处理 VecDoub 向量的旧代码进行接口。尽管最初的 C++ 标准库并未保证这种行为,但所有已知的实现都支持它,而且该行为现在已被标准的一项修正案所要求 [2]。
对于矩阵,我们类似地假设其存储方式是按行存储在一个连续的内存块中。例如:
Int n=97, m=103;
MatDoub a(n,m);
Doub *b = &a[0][0];
这意味着 a[i][j] 和 b[m*i+j] 是等价的。
我们的一些例程需要能够接受一个向量或矩阵的某一行作为参数。为简化起见,我们通常使用重载来实现这一点,例如:
void someroutine(Doub *v, Int m) {
// 用于矩阵行的版本
}
inline void someroutine(VecDoub &v) {
someroutine(&v[0], v.size());
}
对于向量 v,调用形式为 someroutine(v);而对于矩阵 vv 的第 i 行,则调用形式为 someroutine(&vv[i][0], vv.ncols())。虽然在我们的 NRmatrix 实现中,更简单的参数 vv[i] 实际上也能工作,但在某些其他矩阵类中(即使保证了连续存储),单一下标操作的返回类型可能不是 T*,此时该方法可能无法工作。
1.4.3 nr3.h 中的实现
作为参考,以下是 NRvector 的完整声明:
template <class T>
class NRvector {
private:
int nn;
T *v;
public:
NRvector();
explicit NRvector(int n);
NRvector(int n, const T &a);
NRvector(int n, const T *a);
NRvector(const NRvector &rhs);
NRvector & operator=(const NRvector &rhs);
typedef T value_type;
inline T & operator[](const int i);
inline const T & operator[](const int i) const;
inline int size() const;
void resize(int newn);
void assign(int newn, const T &a);
~NRvector();
};
其实现是直接明了的,可以在文件 nr3.h 中找到。唯一需要注意的细节是如何一致地处理零长度向量,以及如何避免不必要的重设大小(resize)操作。
NRmatrix 的完整声明如下:
template <class T>
class NRmatrix {
private:
int nn;
int mm;
T **v;
public:
NRmatrix();
NRmatrix(int n, int m);
NRmatrix(int n, int m, const T &a);
NRmatrix(int n, int m, const T *a);
NRmatrix(const NRmatrix &rhs);
NRmatrix & operator=(const NRmatrix &rhs);
typedef T value_type;
inline T* operator[](const int i);
inline const T* operator[](const int i) const;
inline int rows() const;
inline int ncols() const;
void resize(int newn, int newm);
void assign(int newn, int newm, const T &a);
~NRmatrix();
};
NRmatrix 中有几个实现细节值得说明。私有变量 v 指向的不是一个数据块,而是一个指向各行数据的指针数组。该指针数组的内存分配与实际数据空间的分配是分开的。数据空间作为一个单独的连续块进行分配,而不是为每一行分别分配。对于零大小的矩阵,我们需要分别考虑两种情况:行数为零,或者行数有限但每行的列数为零。例如,其中一个构造函数如下所示:
template <class T>
NRmatrix<T>::NRmatrix(int n, int m) : nn(n), mm(m), v(n > 0 ? new T*[n] : NULL)
{
int i, nel = m * n;
if (v) v[0] = nel > 0 ? new T[nel] : NULL;
for (i = 1; i < n; i++) v[i] = v[i-1] + m;
}
最后,你的编译器是否遵守上述 NRvector 和 NRmatrix 中的 inline 指令非常重要。如果不遵守,那么每次访问向量或矩阵元素时,都可能产生完整的函数调用,包括在处理器中保存和恢复上下文。这几乎等同于使 C++ 在大多数数值计算中变得毫无用处!幸运的是,截至本书撰写时,最常用的编译器在这方面都是“守信”的。
1.5 一些其他约定与功能
本节汇总了对 C++ 语言特性的进一步说明,以及我们在本书中如何使用这些特性。
1.5.1 错误与异常处理
我们已经提到,我们使用简单的 throw 语句来处理错误情况,例如:
throw("error foo in routine bah");
如果你在一个具有明确定义的错误类集合的环境中编程,并且希望使用这些错误类,那么你需要修改所使用例程中的这些行。或者,即使没有任何额外机制,你只需对 nr3.h 做出少量修改,就可以在几种不同但有用的行为之间进行选择。
默认情况下,nr3.h 通过预处理器宏重新定义了 throw():
#define throw(message) \
{printf("ERROR: %s\n in file %s at line %d\n", \
message,__FILE__,__LINE__); \
exit(1);}
这段代码使用了标准 ANSI C(C++ 中也支持)的特性,用于打印出错时的源代码文件名和行号。虽然这种方式不够完善,但完全可以正常工作。
更实用、也更优雅的做法是设置 nr3.h 中的编译器开关 _USENRERRORCLASS_,它会将上述宏替换为以下代码:
struct NRerror {
char *message;
char *file;
int line;
NRerror(char *m, char *f, int l) : message(m), file(f), line(l) {}
};
void NRcatch(NRerror err) {
printf("ERROR: %s\n in file %s at line %d\n",
err.message, err.file, err.line);
exit(1);
}
#define throw(message) throw(NRerror(message,__FILE__,__LINE__));
现在你就拥有了一个(初级的)错误类 NRerror。你可以在代码中任意位置(或多个位置)使用 try...catch 控制结构来使用它,例如(§2.9):
...
try {
Cholesky achol(a);
}
catch (NRerror err) {
NRcatch(err);
}
如上所示,NRcatch 函数的使用只是简单地模仿了之前宏在全局上下文中的行为。但你完全不必使用 NRcatch:你可以在 catch 语句体中替换为你想要的任何代码。如果你想区分可能抛出的不同类型的异常,可以利用 err 中返回的信息。我们留给你自己去探索。当然,你也完全可以向你自己版本的 nr3.h 中添加更复杂的错误类。
1.5.2 常量正确性(Const Correctness)
在 C++ 的讨论中,很少有话题比 const 关键字引发的争论更激烈。我们坚定地相信应尽可能使用 const,以实现所谓的“常量正确性”(const correctness)。如果你在声明那些不应被修改的标识符时加上 const 限定符,许多编码错误会被编译器自动捕获。此外,使用 const 会使你的代码更具可读性:当你看到函数参数前有 const 时,你立刻就知道该函数不会修改该对象;反之,如果没有 const,你就应该预期该对象会在某处被修改。
我们对 const 的信念如此坚定,以至于即使在理论上冗余的地方也会插入 const:如果一个参数以值传递方式传入函数,函数会创建该参数的一个副本。即使函数修改了这个副本,原始值在函数退出后也不会改变。虽然这允许你“不纯净地”修改以值传递的参数,但这种用法容易出错且难以阅读。如果你以值传递某物的意图仅仅是将其作为输入变量,那就应该明确表达这一点。因此,我们会将函数 $f(x)$ 声明为,例如:
Doub f(const Doub x);
如果在函数内部你想使用一个初始化为 x 但随后会被修改的局部变量,请定义一个新变量——不要复用 x。如果你在声明中加上 const,编译器就不会让你犯错。
在函数参数中使用 const 会使你的函数更具通用性:用一个非常量变量调用期望 const 参数的函数属于“平凡转换”(trivial conversion)。但试图将一个常量传递给非常量参数则是错误的。
使用 const 的最后一个原因是它允许进行某些用户自定义的类型转换。正如文献 [1] 中所讨论的,如果你想将 Numerical Recipes 的例程与其他矩阵/向量类库一起使用,这一点会非常有用。
现在我们需要详细说明 const 对于函数参数中非简单类型(例如类)的确切作用。基本上,它保证该对象不会被函数修改。换句话说,对象的数据成员不会被改变。但如果某个数据成员是指向某些数据的指针,而这些数据本身并非成员变量,那么即使指针不能被修改,其所指向的数据仍可能被改变。
让我们看看这对一个以 NRvector<Doub> 作为参数 a 的函数 f 有何影响。为避免不必要的拷贝,我们总是通过引用传递向量和矩阵。考虑以下两种函数参数声明方式的区别:
void f(NRvector<Doub> &a);
void f(const NRvector<Doub> &a);
const 版本承诺 f 不会修改 a 的数据成员。但像下面这样的语句:
a[i] = 4.;
在函数定义内部原则上是完全合法的——你修改的是指针所指向的数据,而不是指针本身。
你可能会问:“难道没有办法保护这些数据吗?”答案是肯定的:你可以将下标运算符 operator[] 的返回类型声明为 const。这就是为什么 NRvector 类中有两个版本的 operator[]:
T & operator[](const int i);
const T & operator[](const int i) const;
第一个版本返回一个可修改向量元素的引用,而第二个版本返回一个不可修改的向量元素(因为返回类型前面有 const)。
但当你只写 a[i] 时,编译器如何知道该调用哪个版本呢?这由第二个版本末尾的 const 关键字指定。它既不指返回的元素,也不指参数 i,而是指调用 operator[] 的对象,在我们的例子中就是向量 a。这两个版本合起来告诉编译器:“如果向量 a 是 const 的,那么将这种 const 性质传递给返回的元素 a[i];否则,就不传递。”
因此,剩下的问题就是编译器如何判断 a 是否为 const。在我们的例子中,a 是函数参数,这很简单:参数要么被声明为 const,要么不是。在其他上下文中,a 可能是 const 的,因为你最初将其声明为 const(并通过构造函数参数初始化),或者因为它是某个其他对象中的 const 引用数据成员,或者出于其他更晦涩的原因。
如你所见,让 const 保护数据稍微有些复杂。从大量遵循这种方案的矩阵/向量库来看,许多人认为这种付出是值得的。我们强烈建议你始终将那些不打算被修改的对象和变量声明为 const。这既包括对象实际创建时,也包括函数声明和定义的参数中。养成 const 正确性(const correctness)的习惯,你绝不会后悔。
在 §1.4 中,我们定义了带有后缀 _I 标签的向量和矩阵类型名,例如 VecDoub_I 和 MatInt_I。其中 _I 表示“函数的输入”,意味着该类型被声明为 const。(这已经在 typedef 语句中完成;你无需重复声明。)相应的标签 _O 和 _IO 则用于提醒你:当参数不仅不是 const,而且实际上会被所在函数修改时,应使用这些标签。
在恰当地强调了 const 正确性的重要性之后,我们也必须承认另一种哲学的存在,即坚持更原始的观点:“const 保护的是容器,而非其内容。” 在这种观点下,你只会需要一种形式的 operator[],即:
T& operator[](const int i) const;
无论你的向量是以 const 引用传递还是非 const 引用传递,都会调用该操作符。在这两种情况下,元素 i 都会被返回为可能可修改的。尽管我们在哲学上反对这种做法,但事实证明,它确实能实现一种巧妙的自动类型转换,使你可以使用自己偏好的向量和矩阵类,而不是 NRvector 和 NRmatrix,即使你的类使用的语法与我们假设的完全不同。有关这种非常专门的应用的更多信息,请参见 [1]。
1.5.3 抽象基类(ABC)还是模板?
在 C++ 中,有时实现某个目标不止一种好方法。坦白地说:总是有不止一种方法。有时这些差异只是细微的调整,但有时却体现了对语言截然不同的看法。当我们做出某种选择,而你更喜欢另一种时,你可能会对我们相当不满。我们对此的辩护是:避免愚蠢的一致性*,并尽可能展示多种观点。
一个很好的例子是:当抽象基类(ABC)和模板的功能重叠时,何时使用哪一种?假设我们有一个函数 func,它可以对(或使用)几种不同类型的对象(称为 ObjA、ObjB 和 ObjC)执行其(有用)的操作。此外,func 并不需要了解与其交互的对象的太多细节,只需要知道该对象具有某个方法 tellme。
我们可以将这种设置实现为一个抽象基类:
struct ObjABC {
virtual void tellme() = 0;
};
struct ObjA : ObjABC {
...
void tellme() {...}
};
struct ObjB : ObjABC {
...
void tellme() {...}
};
struct ObjC : ObjABC {
...
void tellme() {...}
};
void func(ObjABC &x) {
...
x.tellme();
}
另一方面,使用模板,我们可以编写 func 的代码,而无需事先看到(甚至无需知道)它所针对的对象:
template<class T>
void func(T &x) {
...
x.tellme();
}
这看起来显然更容易!但它更好吗?
也许。模板的一个缺点是,每次编译器遇到对 func 的调用时,都必须能够访问该模板。这是因为编译器实际上会为它遇到的每种不同类型的参数 T 编译一个不同的 func 版本。然而,除非你的代码庞大到无法轻松地作为一个单元编译,否则这并不是一个很大的缺点。另一方面,模板的优势在于,虚函数在调用时会产生微小的运行时开销。但这种开销通常并不显著。
在这个例子中,决定性的因素与软件工程有关,而非性能,它们隐藏在省略号($\ldots$)所在的行中。我们尚未真正告诉你 ObjA、ObjB 和 ObjC 之间的关联有多紧密。如果它们关系密切,那么 ABC 方法就提供了将不仅仅是 tellme 的内容放入基类的可能性。将内容(无论是数据还是纯虚方法)放入基类,可以让编译器强制派生类之间的一致性。如果你以后编写了另一个派生对象 ObjD,其一致性也会被强制执行。例如,编译器会要求你在每个派生类中实现基类中每个纯虚方法所对应的方法。
相比之下,在模板方法中,唯一被强制执行的一致性是方法 tellme 的存在,而且这种一致性仅在代码中实际用 ObjD 参数调用 func 的位置(如果存在这样的位置)才会被检查,而不是在定义 ObjD 时检查。因此,模板方法中的一致性检查显得更加随意。
随性的程序员会选择模板。严谨的程序员会选择 ABC。而我们的选择是……视情况而定,有时用这个,有时用那个。此外,还可能存在其他原因(涉及类派生或模板的某些微妙特性),使得一种方法优于另一种。我们将在后续章节中遇到这些情况时指出。例如,在第 17 章中,我们为求解常微分方程(ODE)的各种“步进器”(stepper)例程定义了一个名为 StepperBase 的抽象基类。派生类实现了特定的步进算法,并且它们被模板化,以便可以接受函数或函子参数(参见 §1.3.3)。
1.5.4 NaN 与浮点异常
我们在 §1.1.1 中提到,IEEE 浮点标准包含一种 NaN(Not a Number,非数)的表示。NaN 与正无穷、负无穷以及所有可表示的数字都不同。它既是一种福音,也可能是一种诅咒。
福音在于,拥有一个可以表示“不要处理我”、“缺失数据”或“尚未初始化”等含义的值是非常有用的。要以这种方式使用 NaN,你需要能够将变量设置为 NaN,并且能够测试变量是否已被设置为 NaN。
设置 NaN 很简单。“标准”方法是使用 numeric_limits。在 nr3.h 中,以下代码行:
static const Doub NaN = numeric_limits<Doub>::quiet_NaN();
定义了一个全局值 NaN,因此你可以随意编写如下代码:
x = NaN;
如果你遇到某个编译器未能正确实现此功能(这确实是标准库中一个相当冷门的角落!),那么可以尝试以下方法:
Uint proto_nan[2] = {0xffffcccc, 0x7fffcccc};
double NaN = *(double*)proto_nan;
(这假设了小端字节序行为;参见 §1.1.1),或者更直观地:
Doub NaN = sqrt(-1);
但后者可能会立即抛出异常(见下文),因此可能无法用于此目的。不过,无论采用哪种方式,你通常都能设法在你的环境中获得一个 NaN 常量。
测试 NaN 也需要一点(一次性)实验:根据 IEEE 标准,NaN 被保证是唯一一个不等于其自身的值!
因此,测试 Doub 类型变量 x 是否为 NaN 的“标准”方法是:
if (x != x) // 则 x 是 NaN
(或者通过相等性测试来判断它不是 NaN)。不幸的是,在撰写本文时,某些原本相当不错的编译器并未正确实现这一点。它们转而提供了一个宏 isnan(),当参数为 NaN 时返回 true,否则返回 false。(请仔细检查所需的头文件是 math.h 还是 float.h——这因编译器而异。)
那么,NaN 的“诅咒”是什么呢?问题在于,某些编译器(尤其是 Microsoft 的编译器)在区分静默 NaN(quiet NaN)和信号 NaN(signalling NaN)时,默认行为设计得不够周全。IEEE 浮点标准中定义了这两种 NaN。静默 NaN 应用于上述场景:你可以设置它们、测试它们,并通过赋值甚至其他浮点运算传播它们,而不会触发导致程序中止的异常。另一方面,顾名思义,信号 NaN 应该触发异常。信号 NaN 应由无效操作生成,例如对负数开平方根或取对数,或计算 pow(0., 0.)。
如果所有 NaN 都被视为信号异常,那么你就无法像上面建议的那样使用它们。这虽然令人烦恼,但尚可接受。然而,如果所有 NaN 都被当作静默 NaN 处理(这是撰写本文时 Microsoft 编译器的默认行为),那么你可能会运行一个长时间的计算,最终却发现所有结果都是 NaN——而你却无法定位是哪个无效操作引发了这一连串(静默)NaN 的传播。这就不可接受了,会使调试变成一场噩梦。(如果其他浮点异常(如溢出或除零)也以类似方式传播,也会出现同样的问题。)
针对特定编译器的技巧通常不在我们的讨论范围内。但这个问题如此关键,我们破例说明一下:如果你使用的是 Microsoft 平台,那么在程序开头加入以下代码:
int cw = _controlfp(0, 0);
cw &= ~(EM_INVALID | EM_OVERFLOW | EM_ZERODIVIDE);
_controlfp(cw, MCW_EM);
会将由无效操作、溢出和除零产生的 NaN 转换为信号 NaN,而保留其他 NaN 为静默状态。头文件 nr3.h 中提供了一个编译器开关 _TURNONFPES_,可自动完成此设置。(其他选项包括 EM_UNDERFLOW、EM_INEXACT 和 EM_DENORMAL,但我们认为最好让这些保持静默。)
1.5.5 其他事项
- 向量和矩阵的边界检查,即验证下标是否在有效范围内,代价高昂。它很容易使访问下标元素的时间增加两到三倍。默认情况下,
NRvector和NRmatrix类从不进行边界检查。然而,nr3.h提供了一个编译器开关_CHECKBOUNDS_,可启用边界检查。这是通过预处理器指令实现的条件编译,因此在关闭时不会带来任何性能损失。虽然这种方法不够优雅,但很有效。
C++ 标准库中的 vector 类采用了不同的策略。如果你使用语法 v[i] 访问向量元素,则不会进行边界检查;但如果你使用 at() 方法(即 v.at(i)),则会执行边界检查。这种方法的明显缺点是,当你调试时,很难将一个冗长的程序从一种方式切换到另一种方式。
- 避免不必要地复制大型对象(如向量和矩阵)对性能至关重要,这一点怎么强调都不为过。如前所述,它们在函数参数中应始终以引用方式传递。此外,你还需谨慎对待,甚至完全避免使用返回类型为大型对象的函数。即使返回类型是引用(这本身就很棘手),编译器也常常会创建临时对象(通过拷贝构造函数),而这种创建往往是模糊甚至不必要的。这就是为什么我们经常编写返回类型为
void的函数,并通过一个(例如)MatDoub_O类型的参数来返回“结果”。(当我们确实使用向量或矩阵作为返回类型时,理由要么是代码用于教学目的,要么是开销相对于刚刚完成的大型计算而言可以忽略不计。)
你可以通过给向量和矩阵类添加“检测代码”来检查编译器的行为:在类定义中添加一个静态整型变量,在拷贝构造函数和赋值运算符中递增它,然后在(你认为)不应发生任何拷贝的操作前后观察其值。结果可能会让你大吃一惊。
- Numerical Recipes 中只有两个例程使用三维数组:§12.6 中的
rlf3和 §18.3 中的solvde。文件nr3.h包含了一个基本的三维数组类,主要是为了支持这两个例程。在许多应用中,更好的做法是声明一个矩阵的向量,例如:
vector<MatDoub> threedee(17);
for (Int i = 0; i < 17; i++) threedee[i].resize(19, 21);
这实际上创建了一个大小为 $17 \times 19 \times 21$ 的三维数组。你可以通过 threedee[i][j][k] 访问各个分量。
- “为什么没有命名空间?” 专业级程序员会注意到,与第二版不同,本第三版《Numerical Recipes》并未将函数和类名置于
NR::命名空间中加以保护。因此,如果你大胆地#include了书中每一个文件,就会向全局命名空间注入大约 500 个名称,这显然是个糟糕的做法!
原因很简单:我们的绝大多数用户并非专业级程序员,大多数人觉得 NR:: 命名空间令人厌烦且容易混淆。正如我们在 §1.0.1 中强烈强调的那样,《Numerical Recipes》不是一个程序库。如果你想为 NR 创建自己的命名空间,请随意。
- 在遥远的过去,《Numerical Recipes》曾支持以 1 为起始下标(而非 0)的数组索引。最后一个支持该特性的版本发布于 1992 年。如今,以 0 为起始的数组已被普遍接受,我们不再支持其他选项。
参考文献
Numerical Recipes Software 2007, "Using Other Vector and Matrix Libraries," Numerical Recipes Webnote No. 1, at http://www.nr.com/webnotes?1[1]